LiveAI SaaS · Solo-built
Grmpt
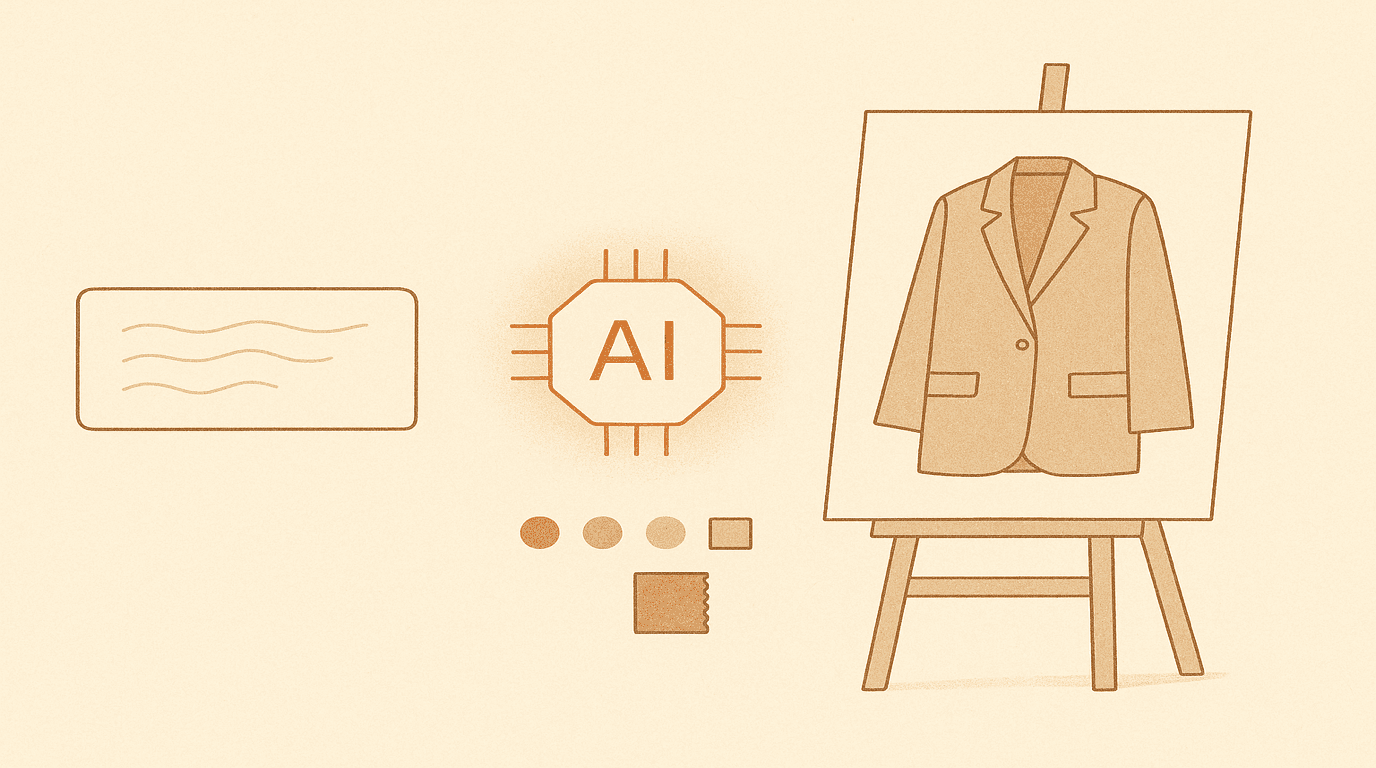
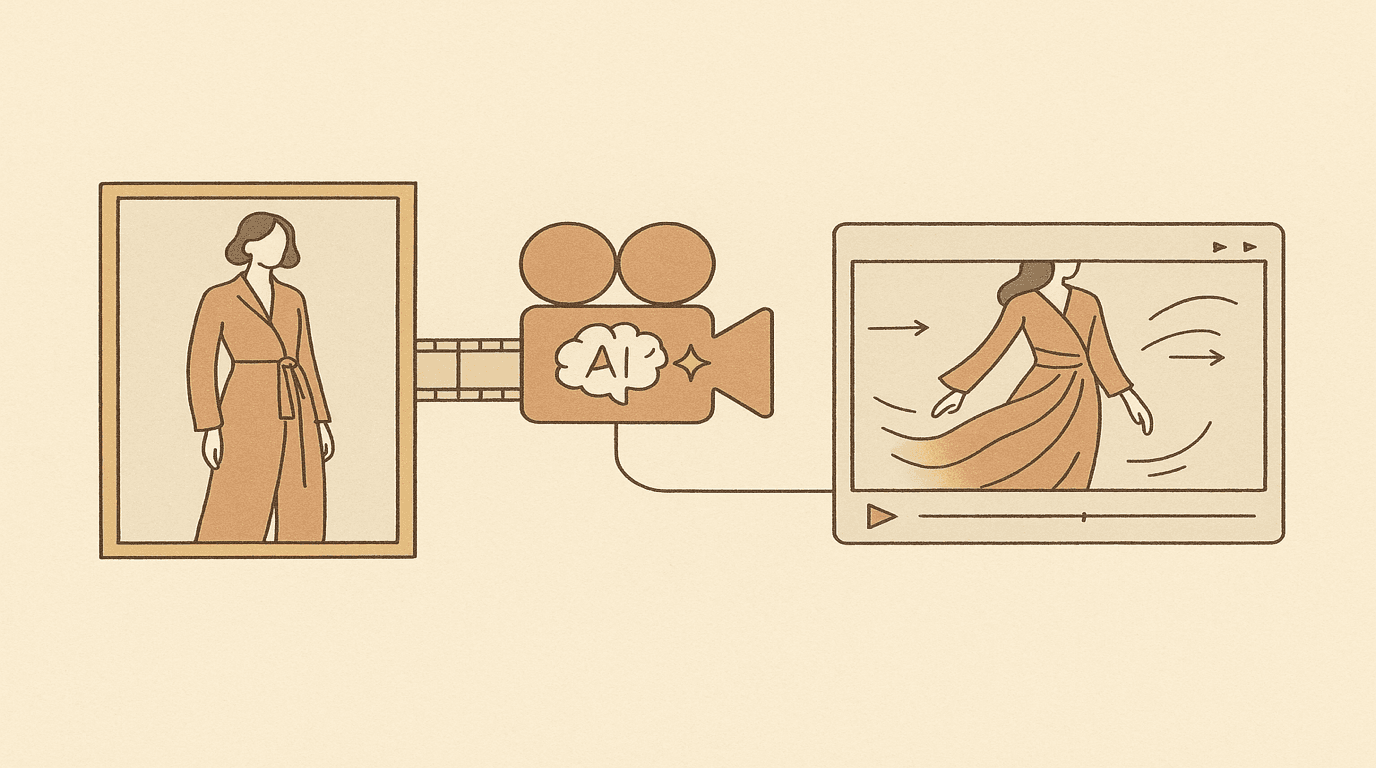
AI fashion design studio — from text prompt to runway video.
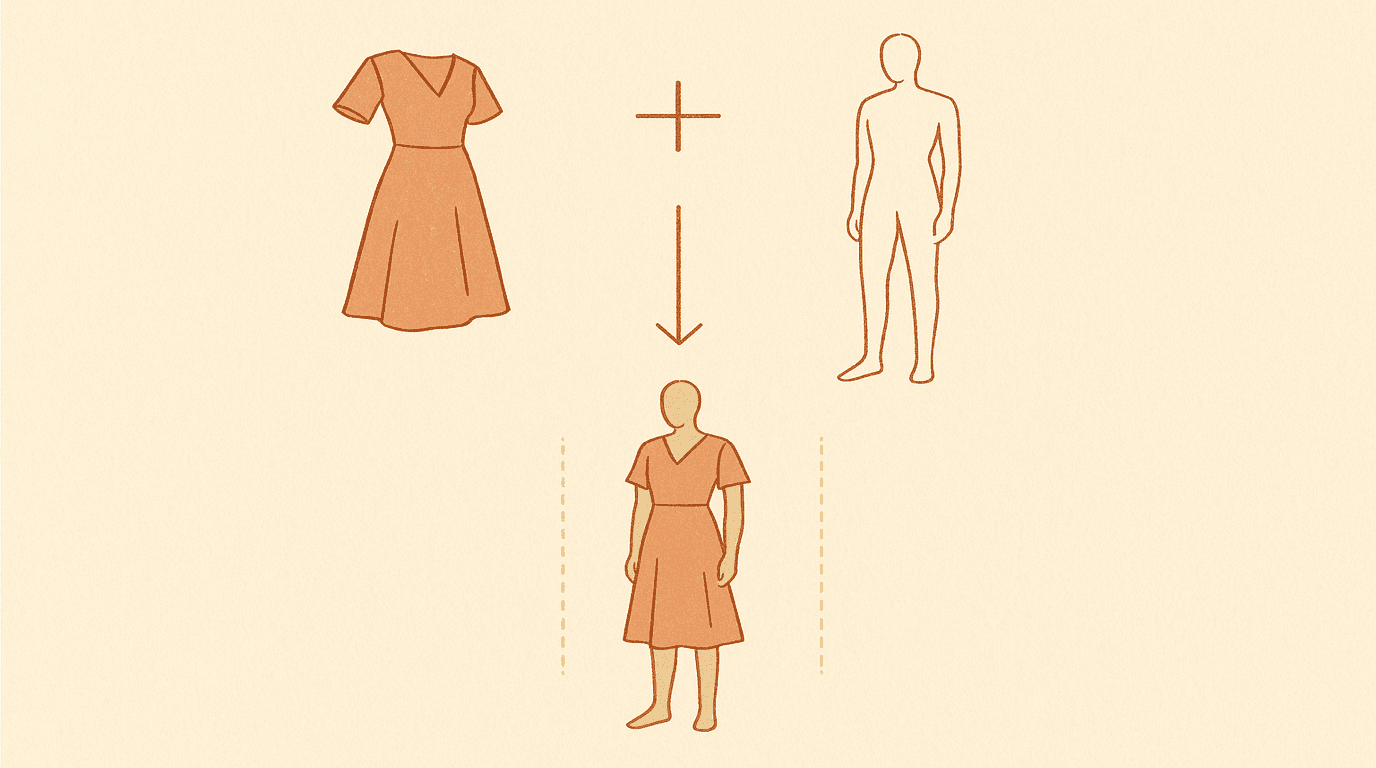
A production SaaS where designers generate garment designs from text or sketches, composite virtual try-ons onto custom AI models, and animate the results into 1080p fashion film. Solo-built and operated: async FastAPI backend, Next.js frontend, Stripe metered billing, and multi-provider AI routing across Gemini, OpenAI, and Kling.
Next.js 16React 19FastAPIPostgreSQLStripeGeminiKling 3.0AWS